综合性学习的粒子群优化算法(CLPSO)文章+源码解析-matlab
费脑筋的matlab代码
1. CLPSO
文章:
Liang J J, Qin A K, Suganthan P N, et al.Comprehensive learning particle swarm optimizer for global optimization of multimodal functions[J].
IEEE Transactions on Evolutionary Computation,2006, 10 (3): 281-295.
对于原始的PSO相比, 去掉了全局最优项, 由原来的向全局最优学习, 变成了向近邻最优值学习.
对于每个粒子, 按照交叉概率Pc随机分配需要学习的近邻粒子列表. 并且一开始设置好所需要学习的近邻参数, 如果全部维度学习粒子都是自己本身, 那么随机分配一个维度学习其他粒子.
当某一粒子m代都未产生更优的pbest(粒子历史最优), 重新分配(更新)粒子所需要学习近邻的列表
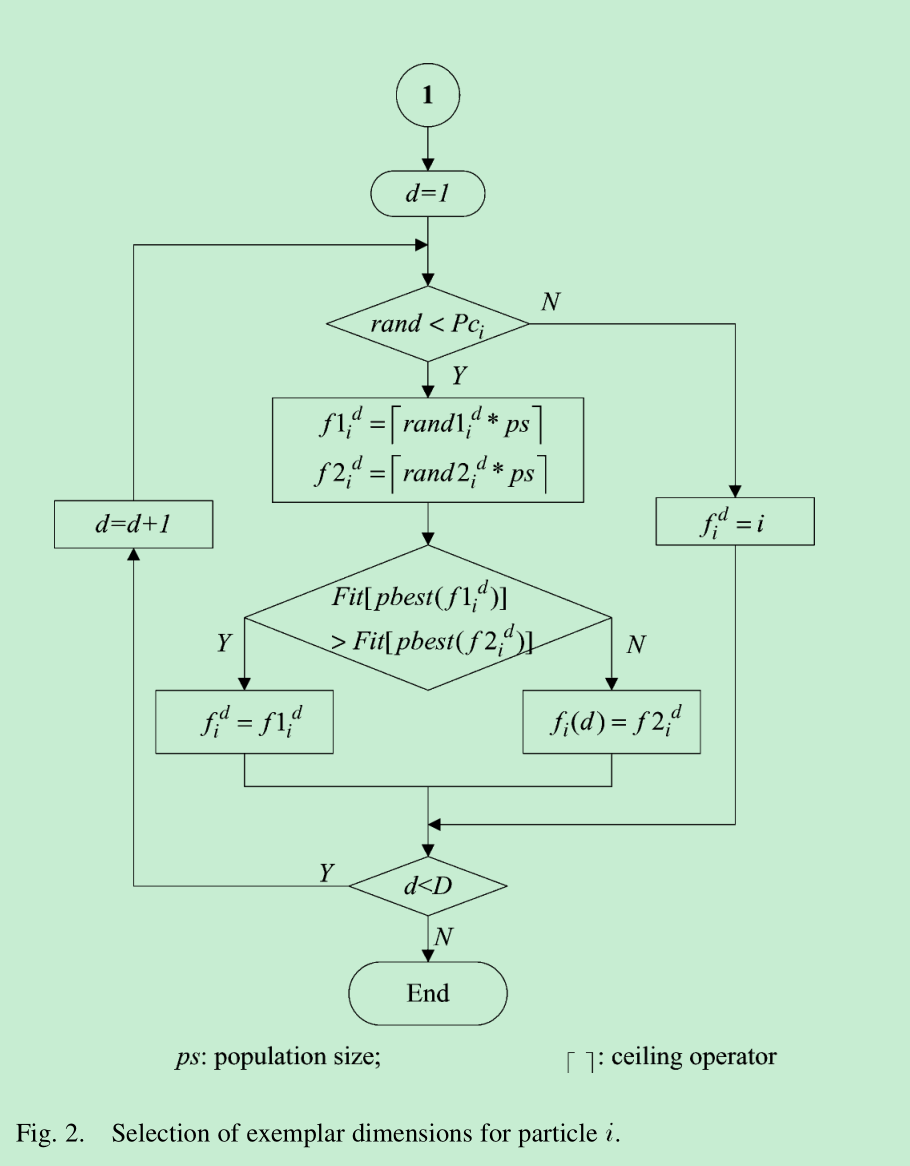
图: 对于近邻粒子的选取原则
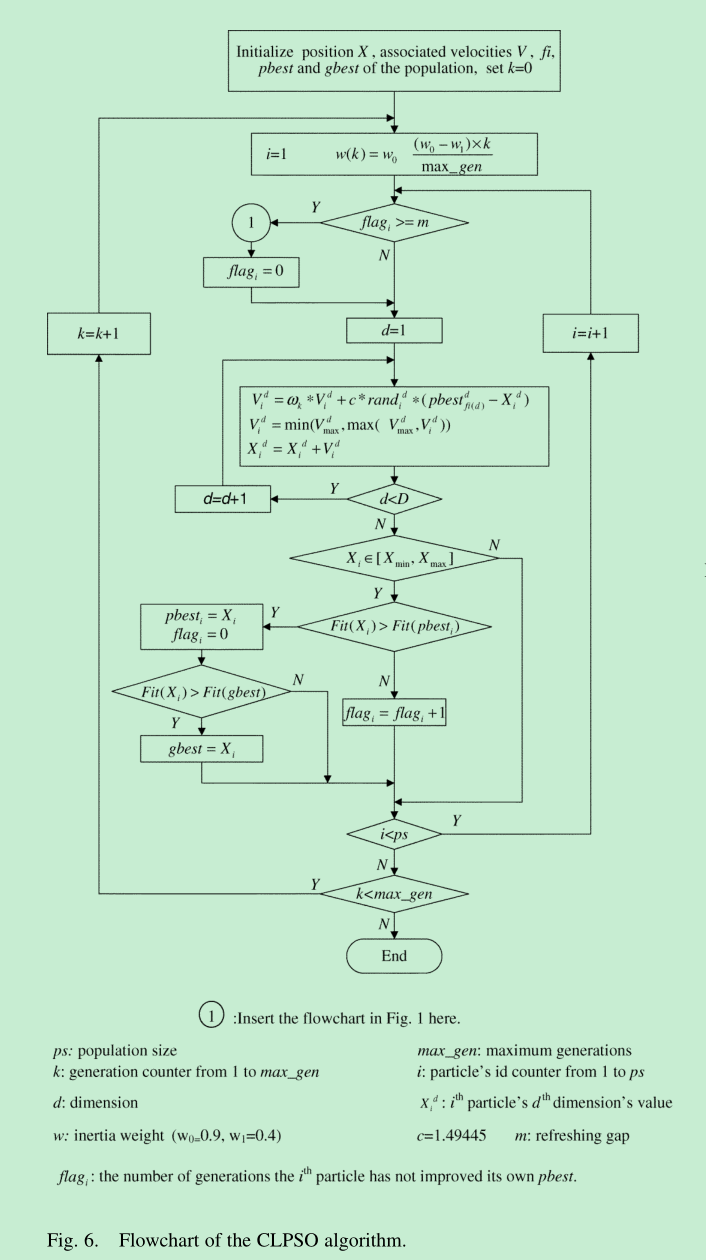
图: 整体的代码逻辑
2. matlab代码解析
坑太多, 加上一开始以为每次迭代, 粒子学习近邻列表都需要更新, 结果是累积m代才更新, m 论文说为7, 源码是5;
首先是论文公式与论文配图不对应
然后是论文参数和源码参数不对应
最后代码很乱, 缩进都没有, 代码也不能直接运行起来, 还要注释几个出错但没啥用的地方
最后通过debug理解了.
学完了matlab的源码, 我滴乖乖, 终于理解了面向对象为什么说很形象很容易理解了
相比于这种矩阵, 面向过程的matlab, 面向对象可太容易理解了
不知道底层速度如何, 有些矩阵的使用确实很厉害, 省去了if else, 但丢失了可读性
% 源码是一个function, 在另一个文件里调用
function [gbest,gbestval,fitcount]= CLPSO_new_func(fhd,Max_Gen,Max_FES,Particle_Number,Dimension,VRmin,VRmax,varargin)
%[gbest,gbestval,fitcount]= CLPSO_new_func('f8',3500,200000,30,30,-5.12,5.12)
% 初始化随机数, 防止重复, 觉得没啥用
rand('state',sum(100*clock));
% me: 最大迭代次数
me=Max_Gen;
% ps: 种群大小/粒子数
ps=Particle_Number;
% D: 维度
D=Dimension;
% cc: c1和c2加速因子, 后面重新赋值了, 这里的没用
cc=[1 1]; %acceleration constants
% 按照非线性曲线生成Pc, 和论文原图一样, 0 -- 0.5之间
t=0:1/(ps-1):1;t=5.*t;
Pc=(0.5).*(exp(t)-1)./(exp(t(ps))-1);
% Pc=0.5.*ones(1,ps); 源码注释
% m: 一个没鸟用的参数,应该用来后续控制矩阵变量维度吧, 0.*ones() 不就是zeros(), 脱裤子放屁
m=0.*ones(ps,1);
% 按照线性递减设置w的值, 初始到结束 :0.9 ~ 0.2; 论文里写的0.9 ~ 0.4,牛逼
iwt=0.9-(1:me)*(0.7/me);
% iwt=0.729-(1:me)*(0.0/me);
cc=[1.49445 1.49445];
% 对于传入function的参数判断, 生成位置限制矩阵
% VRmin: 位置最小矩阵
% VRmax: 位置最大矩阵
if length(VRmin)==1
VRmin=repmat(VRmin,1,D);
VRmax=repmat(VRmax,1,D);
end
% 生成最大速度矩阵,位置范围的20%
% Vmin, Vmax: 最小和最大速度矩阵
mv=0.2*(VRmax-VRmin);
% 同步到每个粒子
VRmin=repmat(VRmin,ps,1);
VRmax=repmat(VRmax,ps,1);
Vmin=repmat(-mv,ps,1);
Vmax=-Vmin;
% 初始化随机生成位置
pos=VRmin+(VRmax-VRmin).*rand(ps,D);
% 调用计算函数生成位置对应的Fitness
% e:fitness, D行1列的fitness矩阵
for i=1:ps;
e(i,1)=feval(fhd,pos(i,:),varargin{:});
end
% Max_FES: 最大适应度评估; fitcount用来计数已经计算了多少次粒子; 下面解释抄的csdn
% 优化算法中常用的有两个终止条件,即最大适应度评估(maximum fitness evalutions)和最大迭代次数,这两个终止条件的关系可以大致写为:
% 最大适应度评估=最大迭代次数*种群数;
% 但由于很多算法每次产生的种群并不是固定的,可能通过变异等操作产生了新的种群,那么这时候这个新种群也要进行适应度评估,即计算适应度值。
fitcount=ps;
% vel: 速度; 初始化
vel=Vmin+2.*Vmax.*rand(ps,D);%initialize the velocity of the particles
% pbest: 粒子历史最优位置; 初始化
pbest=pos;
% pbestval: 粒子历史最优fitness(适应值); 初始化
pbestval=e; %initialize the pbest and the pbest's fitness value
% gbestval: 全局最优fitness
% gbest: 全局最优位置
% gbestid: 全局最优位置的粒子id
[gbestval,gbestid]=min(pbestval);
gbest=pbest(gbestid,:);%initialize the gbest and the gbest's fitness value
gbestrep=repmat(gbest,ps,1);
% stay_num: 未进化代数矩阵, 用来记录粒子已经多少次没有更新pbest了
stay_num=zeros(ps,1);
% ai: 没鸟用的, 一直是0; 可能是想要实现更智能的过程, 但没有实现
ai=zeros(ps,D);
% f_pbest: 需要学习的近邻粒子矩阵
f_pbest=1:ps;
f_pbest=repmat(f_pbest',1,D);
% 初始化f_pbest, 感觉这步和后面的重复, 直接一开始设置stay_num=5不就行了
for k=1:ps
% ar 没啥用的参数, 一直为0
ar=randperm(D);
% ai 没啥用的参数, 一直为0
ai(k,ar(1:m(k)))=1;
% fi1随机学习的粒子1
fi1=ceil(ps*rand(1,D));
% fi2随机学习的粒子2
fi2=ceil(ps*rand(1,D));
% fi: 学习的粒子; 通过比较1,2适应值选取最优的粒子
fi=(pbestval(fi1)<pbestval(fi2))'.*fi1+(pbestval(fi1)>=pbestval(fi2))'.*fi2;
% bi: 每个维度的是否向近邻学习; 是为1, 否为2
bi=ceil(rand(1,D)-1+Pc(k));
% bi全都是0, 随机一个维度学习近邻
if bi==zeros(1,D),rc=randperm(D);bi(rc(1))=1;end
% 初始化学习近邻矩阵
f_pbest(k,:)=bi.*fi+(1-bi).*f_pbest(k,:);
end
% 没用的参数, 莫名其妙的
stop_num=0;
% i: 已迭代次数
i=1;
% 这个判断写的很孬, 和后面代码重复了
while i<=me&&fitcount<=Max_FES
i=i+1;
% 计算每个粒子
for k=1:ps
% 更新近邻判断; 我认为重复的代码
if stay_num(k)>=5
% if round(i/10)==i/10%|stay_num(k)>=5
stay_num(k)=0;
ai(k,:)=zeros(1,D);
f_pbest(k,:)=k.*ones(1,D);
ar=randperm(D);
ai(k,ar(1:m(k)))=1;
fi1=ceil(ps*rand(1,D));
fi2=ceil(ps*rand(1,D));
fi=(pbestval(fi1)<pbestval(fi2))'.*fi1+(pbestval(fi1)>=pbestval(fi2))'.*fi2;
bi=ceil(rand(1,D)-1+Pc(k));
if bi==zeros(1,D),rc=randperm(D);bi(rc(1))=1;end
f_pbest(k,:)=bi.*fi+(1-bi).*f_pbest(k,:);
end
% pbest_f: 由近邻矩阵得到的所有近邻各维度的位置
for dimcnt=1:D
pbest_f(k,dimcnt)=pbest(f_pbest(k,dimcnt),dimcnt);
end
% gbestrep: 根本没用上, 一开始这里也让我懵逼了好久; 后面看到一个博客解释这里没用上, 加上后面debug过程明白了
% 真滴坑, ai=0
aa(k,:)=cc(1).*(1-ai(k,:)).*rand(1,D).*(pbest_f(k,:)-pos(k,:))+cc(2).*ai(k,:).*rand(1,D).*(gbestrep(k,:)-pos(k,:));%~~~~~~~~~~~~~~~~~~~~~~
% 更新速度
vel(k,:)=iwt(i).*vel(k,:)+aa(k,:);
vel(k,:)=(vel(k,:)>mv).*mv+(vel(k,:)<=mv).*vel(k,:);
vel(k,:)=(vel(k,:)<(-mv)).*(-mv)+(vel(k,:)>=(-mv)).*vel(k,:);
% 更新位置
pos(k,:)=pos(k,:)+vel(k,:);
% pos位置在范围内才计算fitness, 和其他Pso算法不一样
if (sum(pos(k,:)>VRmax(k,:))+sum(pos(k,:)<VRmin(k,:)))==0;
e(k,1)=feval(fhd,pos(k,:),varargin{:});
% 更新fitcount
fitcount=fitcount+1;
tmp=(pbestval(k)<=e(k));
if tmp==1
stay_num(k)=stay_num(k)+1;
end
% 为什么都用这种0,1矩阵呢, 虽然看起来很牛逼, 但可读性远远不如if else
temp=repmat(tmp,1,D);
% 更新
pbest(k,:)=temp.*pbest(k,:)+(1-temp).*pos(k,:);
% 更新
pbestval(k)=tmp.*pbestval(k)+(1-tmp).*e(k);%update the pbest
% 更新, 这个怎么不用0,1矩阵了
if pbestval(k)<gbestval
gbest=pbest(k,:);
gbestval=pbestval(k);
gbestrep=repmat(gbest,ps,1);%update the gbest
end
end
end
% 没用的判断, while大循环干什么吃的
if fitcount>=Max_FES
break;
end
% Max_FES和Max_Gen都要满足
% 这个也没必要, 在while循环里写成或形式不就行了; while (i <= Max_Gen || fitcount <= Max_FES)
if (i==me)&&(fitcount<Max_FES)
i=i-1;
end
end
gbestval